DDA3020 Machine Learning
Information Theory
Informaion
When , , which means there is no uncertainty, then no information.
Entropy
Entropy is defined as the expected value of information from a source.
Cross-entropy
Cross-entropy measures average bits needed to encode events from true distribution using estimated distribution .
Property 1
Proof
.
Property 2
Proof
By Jensen equality, for any convex function , .
Since is concave, we can implies Let , then The equality holds only when .
Kullback-Leibler divergence (KL-divergence)
The distance between two distributions.
Property 1
Proof
Property 2
Linear Regression
Modeling of Linear Regression
Deterministic Perspective
Find which minimizes the following expression:
Probabilistic Perspective
where is called obervation noise or residual error. The output can also be seen as a random variable, whose conditional probability is :
Given the training dataset , by maximum log-likehood estimaiton, we get
Solutions of Linear Regression
Analytical solution
Let , then
Differentiating with respect to and setting the result to :
If is invertible then
For linear regression with multiple outputs, , then
Gradient Descent
, can be updated by gradient descent algorithm:
Classification
Binary Classification
If is invertible then , .
Multi-Category Classification
Each ro in has a one-hot assignment, then If is invertible then , .
Linear Regression Models
Ridge Regression
where (The bias should not be normalized).
To get ,
Where is the identity matrix with the top-left element set to 0 to avoid penalizing the bias term .
We can assume that the parameter follow a zero-mean Gaussian prior (omit the bias ).
Utilizing this prior, we obtain the maximum a posteriori (MAP) estimation
Polynomial Regression
Note that is still a linear function .
Lasso Regression
, then we have
Ridge uses L2 penalty, shrinking weights towards zero without feature selection. In contrast, Lasso uses L1 penalty, forcing some weights to exactly zero, achieving model sparsity and automatic feature selection.
Robust Linear Regression
Adpot the loss as follows .
Assuming that , .
Two ways to make it differentiable:
-
.
-
By using the following equation .
Then it can be reformulated as follows:
Given , ; Given , .
Comparison
| Regression Method | ||
|---|---|---|
| Gaussian | Uniform | Least squares |
| Gaussian | Gaussian | Ridge regression |
| Gaussian | Laplace | Lasso regression |
| Laplace | Uniform | Robust regression |
| Student | Uniform | Robust regression |
Logistic Regression
Hypothesis Function
The decision boundary satisfies when , and when , , it is determined by .
Cost Function
-
Loss
-
Linear Regression
,
-
Logistic Regression
-
-
Cross-entropy Loss
For , ,.
For , ,.
Gradient Descent
Assume samples in total. Learning by minimizing
By gradient descent
Multi-class Classification
Softmax
Cost Function
Regularized Logistic Regression
Linear Regression vs Logistic Regression
| Dimension | Linear Regression | Logistic Regression |
|---|---|---|
| Task Type | Regression task predicting continuous real values | Classification task predicting discrete class labels |
| Model Hypothesis | Linear function Output range | Sigmoid-mapped linear function Output range (posterior probability of positive class) |
| Loss Function | Residual sum of squares (MSE) | Cross-entropy loss |
| Solution Method | Closed-form solution or gradient descent | No closed-form solution, optimized via gradient descent |
Supoort Vector Machine
Larger Marigin
Denote is a hyperplane, then is orthogonal to the hyperplane, and has the distance to the hyperplane.
Margin is defined as the distance between the hyperplane and the closest data point, which can be formulated as with .
Since . Set , then , the margin is (Scaling by any positive constant does not change the geometric margin ).
Then the optimization problem can be formulated as follows:
Hinge Loss
Let where be the hypothesis function, then the cost function can be defined as follows:
The hinge loss is defined as follows
Then the optimization problem can be reformulated as follows
Largrange Duality
The objective function of SVM is
Its Lagrangian function is defined as follows
The KKT conditions are as follows
Then the Largangian function can be reformulated as follows
Then the dual problem is obtained as follows
The data points with are called support vectors, which locate on the margin and determine the decision boundary. Let be the set of support vectors, then the decision boundary can be determined by any support vector as follows:
SVM with Slack Variables
In this case, the optimization problem can be formulated as follows
Its Lagrangian function is defined as follows
The KKT conditions are as follows
The the Lagrange function can be reformulated as follows
The dual problem can be reformulated as follows
Let . The bias parameter can be determined by any support vector with as follows
| Condition on | Slack | Contributes to classifier? | Correctly classified? | Location relative to margin / decision boundary |
|---|---|---|---|---|
| No | Yes | Outside the margin | ||
| Yes | Yes | On the margin | ||
| Yes | Yes | Inside the margin, not crossing decision boundary | ||
| Yes | No | Crossing decision boundary |
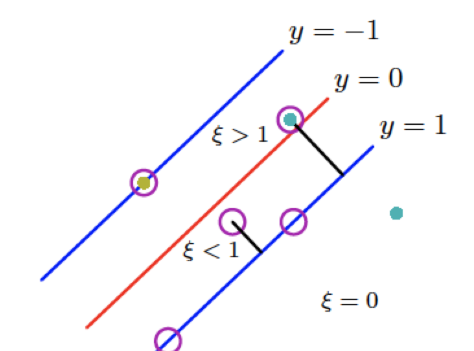
SVM with Kernels
Define the kernel function , then the dual problem can be reformulated as follows
The solution becomes
The prediction of new data becomes
Some kernel functions
Multi-class SVM
Predict the label of as , , use one-vs-rest strategy to train binary SVM classifiers.
Tree-based Methods
Decision Tree
A decision tree (non-parametric model) is a hierarchical model for supervised learning whereby the local region is identified in a sequence of recursive splits.
Classification Tree
-
Impurity Measure (Choose the attribute that maximizes the reduction in impurity.)
Let be the seef of instances of belonging to class (), then is the proportion of class in .
Entropy is the measurement of impurity, which is defined as follows
And the entropy of given the condition of attribute is defined as follows (Suppose attribute to split into subsets )
Information gained by branching on atribute is defined as follows
-
Gini Index
Gini index is another measurement of impurity, which is defined as follows
It means the probability of different class labels for two randomly selected instances from .
And the Gini index of given the condition of attribute is defined as follows (Suppose attribute to split into subsets )
Gini gain by branching on atribute is defined as follows
Regression Tree
The regression tree grows by recursively selecting the binary split on any variable that most reduces the sum of squared errors.
is the prediction for leaf , where is the number of instances in leaf .
-
Mean Squared Error (MSE)
The total MSE is .
-
Sum of squared Errors (SSE)
The total SSE is .
Overfitting and Pruning
Pruning of the decision tree is one by replacing a subtree with a leaf node. The subtree is replaced if the error of the subtree on the validation set is larger than the error of the leaf node on the validation set.
Ensemble Models
Bagging
Sample records with replacement from the training set to create multiple bootstrap samples, and train a base model on each bootstrap sample. The final prediction is obtained by averaging the predictions of all base models.
It aggreates the predictions of all single trees and produces many correlated trees, which the diversity of the trees is not high.
Random Forest
It chooses a random subset of features to split each node, which increases the diversity of the trees and reduces the correlation between trees.
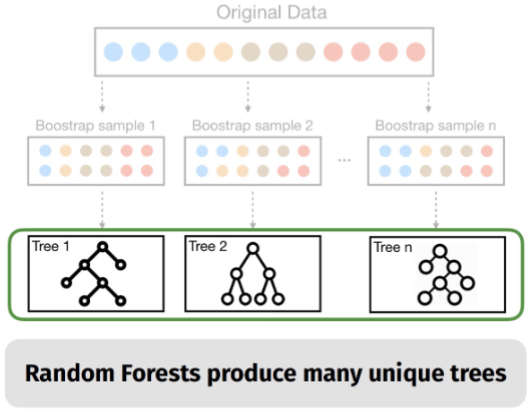
Neural Networks
Activation Function
Perceptron Model
, the objective function is , and the update rule is .
For a new data point , the prediction is , which is a linear classifier.
Multi-layer Feedforward Neural Networks
To solve XOR, a one‑hidden‑layer network learns non‑linear input features. Each layer re‑expresses the previous layer’s output, progressively extracting more abstract and discriminative features.
, where is the transformation of layer .
Backpropagation (using computational graph (CG))
Forward Pass
For each , compute as a function of its parents.
Backward Pass
, then for , . Also update parameters by
where is the cost function of layer .
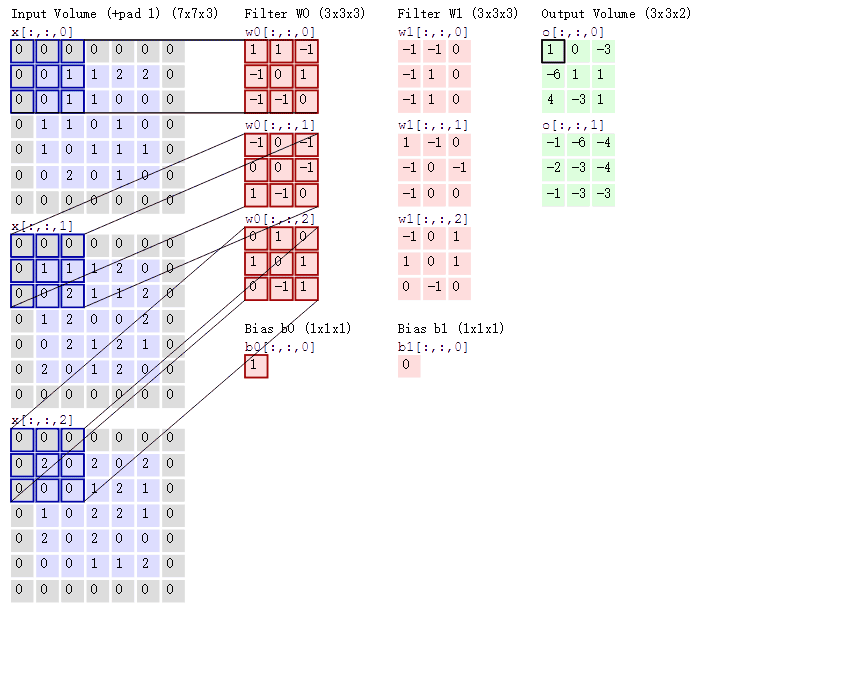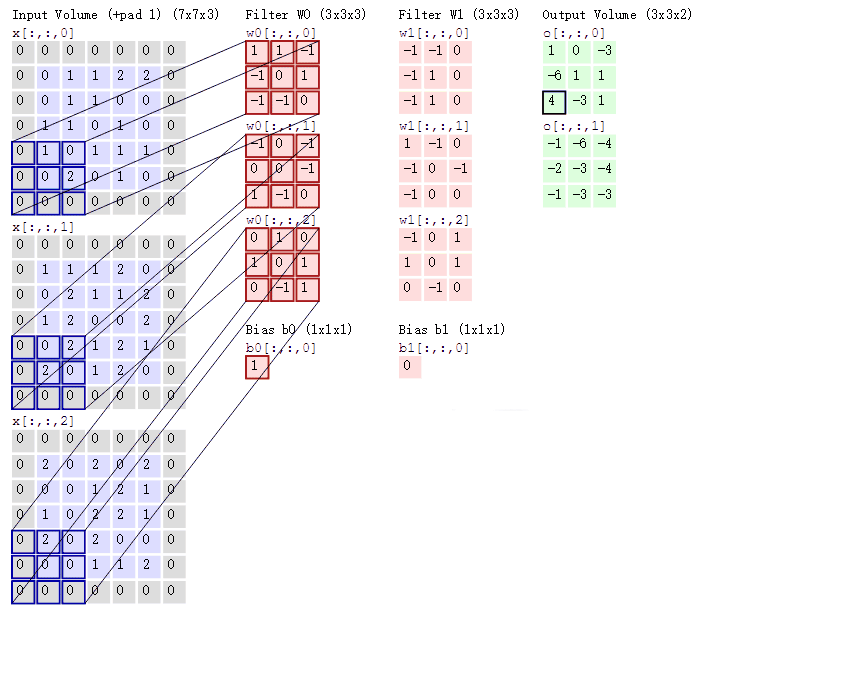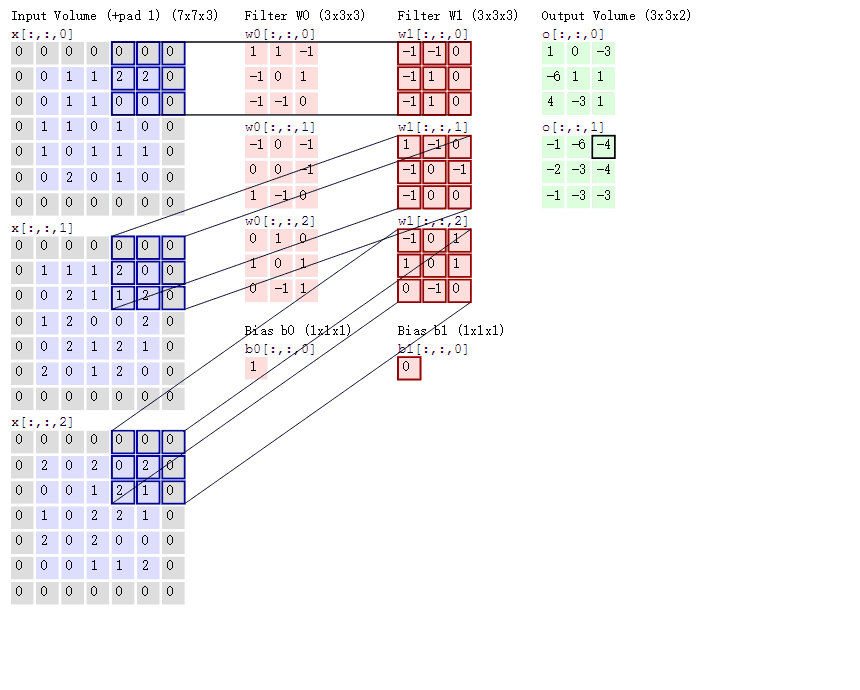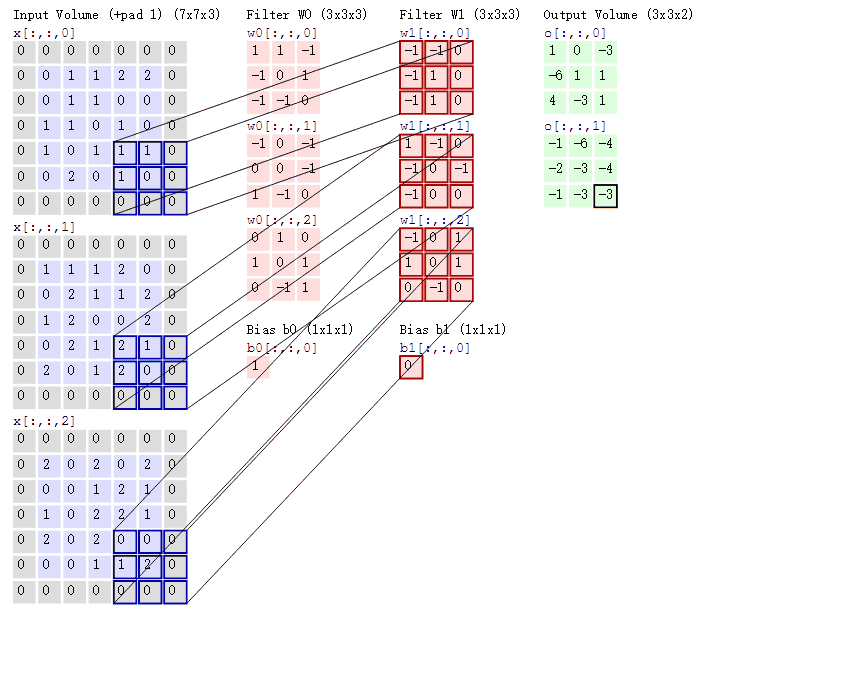
Convolutional Neural Networks
Convolutional Layer
Input volume is .
A convolutional layer has four hyperparameters: number of filters , filter size , stride , and zero padding (per side).
Output spatial size is and .
Output volume is .
Number of parameters is weights plus biases.
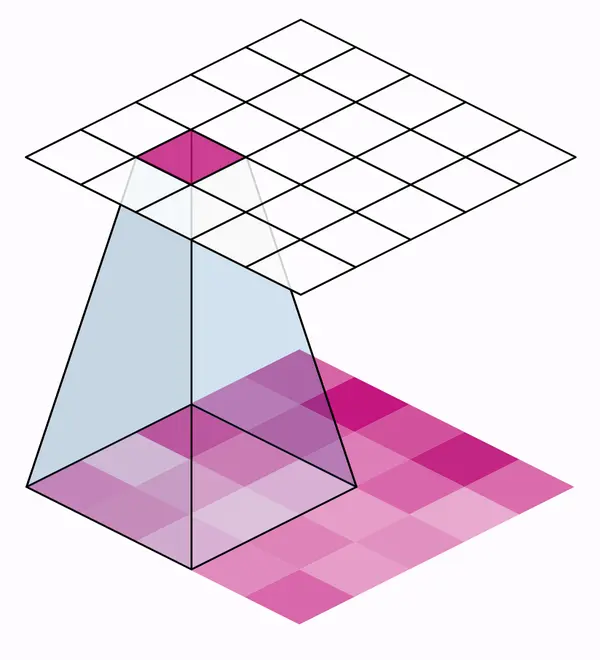
|
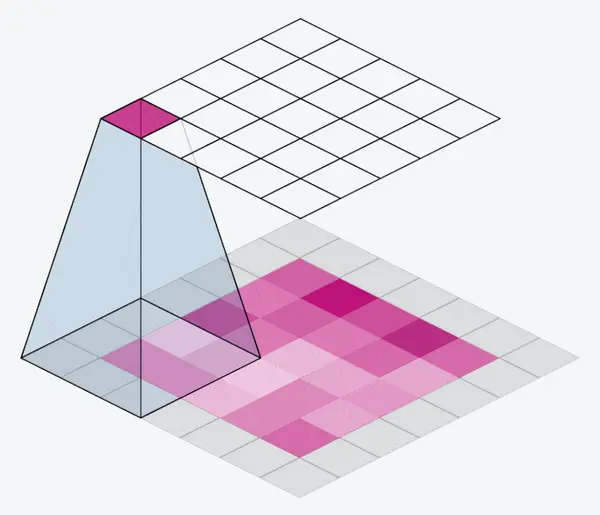
|
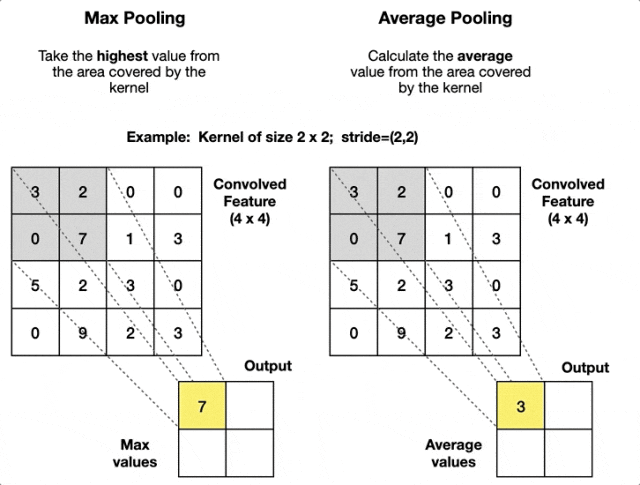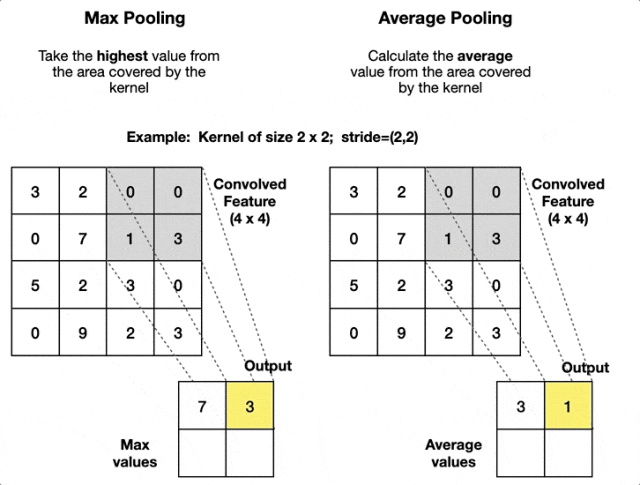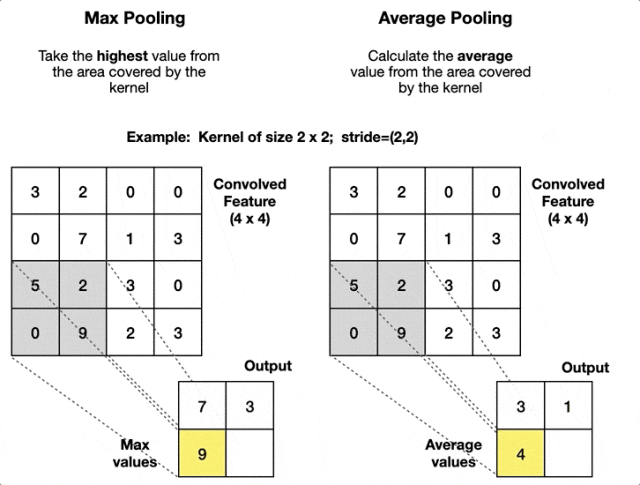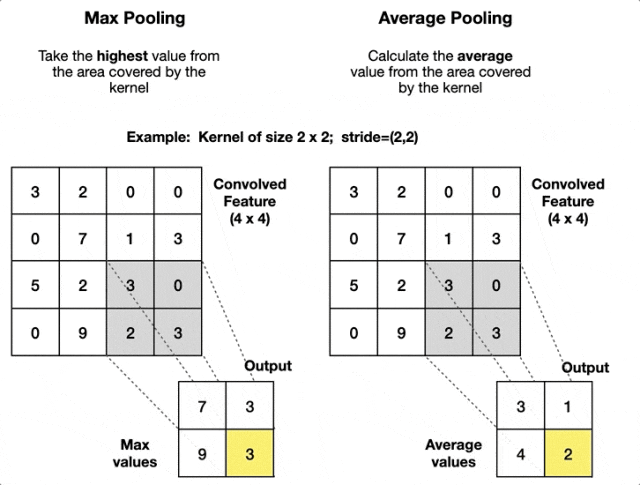
Pooling Layer
Pooling layer has no learnable parameters. Hyperparameters are filter size and stride .
Output spatial size is and .
Pooling operates on each channel independently, so output volume is .
Common pooling functions are and .
Fully Connected Layer
A fully connected layer computes the class scores, resulting in an output volume of , where is the number of classes, which contains neurons that connect to the entire input volume.
Recurrent Neural Networks and Transformer
RNN
Basic
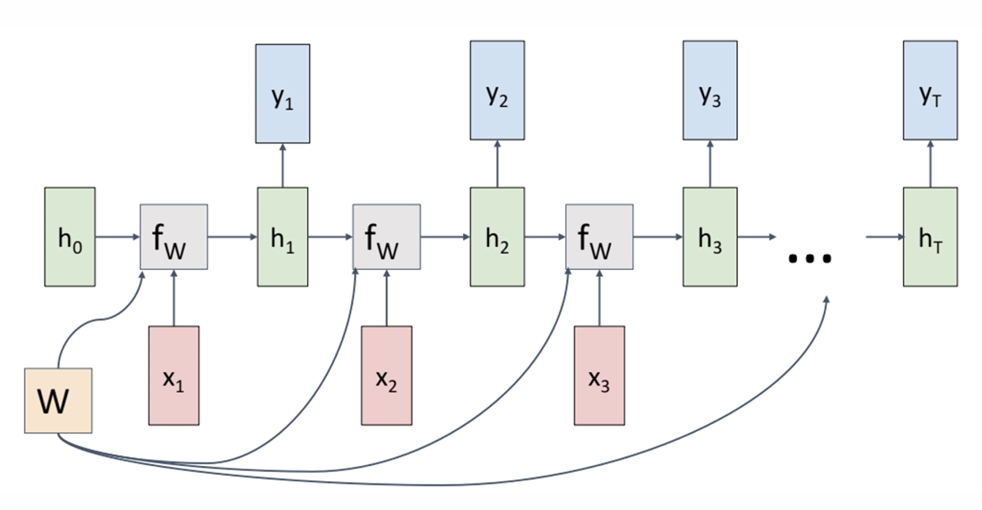
, , where is the transition function and is the output function. The cost/error function is , where .
However, the basic RNN suffers from vanishing/exploding gradient problem, which makes it difficult to learn long-term dependencies.
Long Short-Term Memory (LSTM)
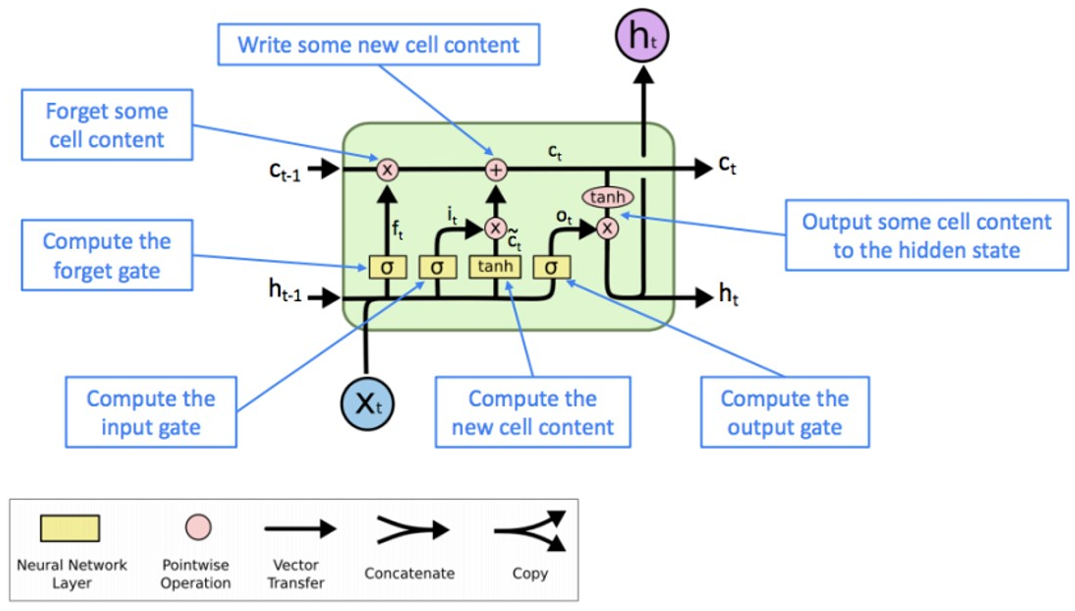
Limitations
- Difficulty with Long-Term Dependencies
- Limited Parallelization
Transformer
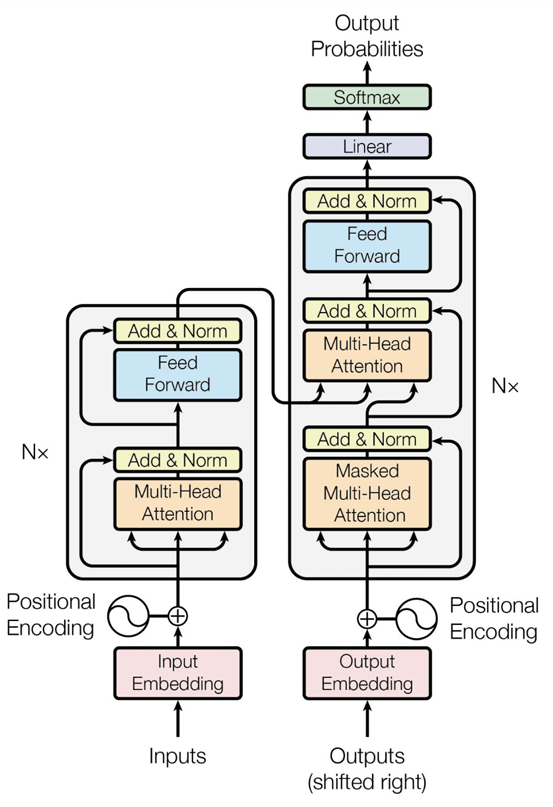
Attention Mechanism
Let be the query, key, and value matrices, where and is the input sequence. Then the attention output is defined as follows
Multi-head Attention
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions, capturing diverse types of relationships in parallel.
Bias-variance Tradeoff
Let be training dataset drawn from , be the model trained by algorithm on .
-
expected test error for a fixed model .
-
expected test error for the algorithm .
-
the expected test error . (mean squared error (MSE))
Now decompose the second term , .
-
Comparsion
Term Description Variance Measures how much the predictions of a model vary when trained on different training sets. (model's sensitivity to the specific training data) Bias² Measures how far the average prediction of a model is from the true value. (model's systematic error) Noise Measures how much the observed values vary around the true target function due to randomness in the data. (data's inherent unpredictability) 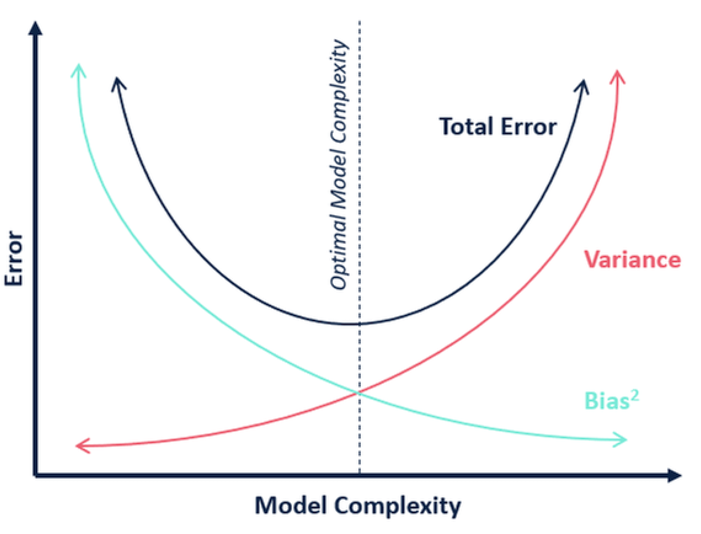
Performance Evaluation
Hyper-parameter Tuning
Determined typically outside the learning algorithms rather than earned by a learning algorithm based on the trainingset.
Cross-validation
Cross-validation is a statistical method of evaluating generalization performance that is more stable and thorough than using a split into a training and a test set.
-
K-fold cross validation
Split the train data into folds, try each fold as validation, while other folds as train. Note that is a hyper-parameter.
Evaluation Metrics
Regression
- Mean Square Error
- Mean Absolute Error
Classification
-
Confusion Matrix
Actual \ Predicted (Predicted) (Predicted) (Actual) (Actual) -
Accuracy The total number of correctly classified samples over all samples under evaluation.
-
Precision The proportion of correctly predicted positive samples among all samples predicted as positive.
-
Recall The proportion of correctly predicted positive samples among all actual positive samples.
-
Cost-sensitive Accuracy (different classes may have different importance)
-
Binary Classification
Metric Formula (True Positive Rate) (False Negative Rate) (True Negative Rate) (False Positive Rate) If positive and negative classes are balanced, then .
As the decision threshold varies from to , FPR decreases while FNR increases, and their intersection point where equals is called the Equal Error Rate (). The lower the , the better the classifier.
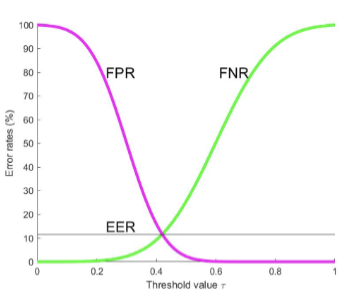
-
-
Receiver Operating Characteristic Curve (ROC) The relationship between TPR and FPR.
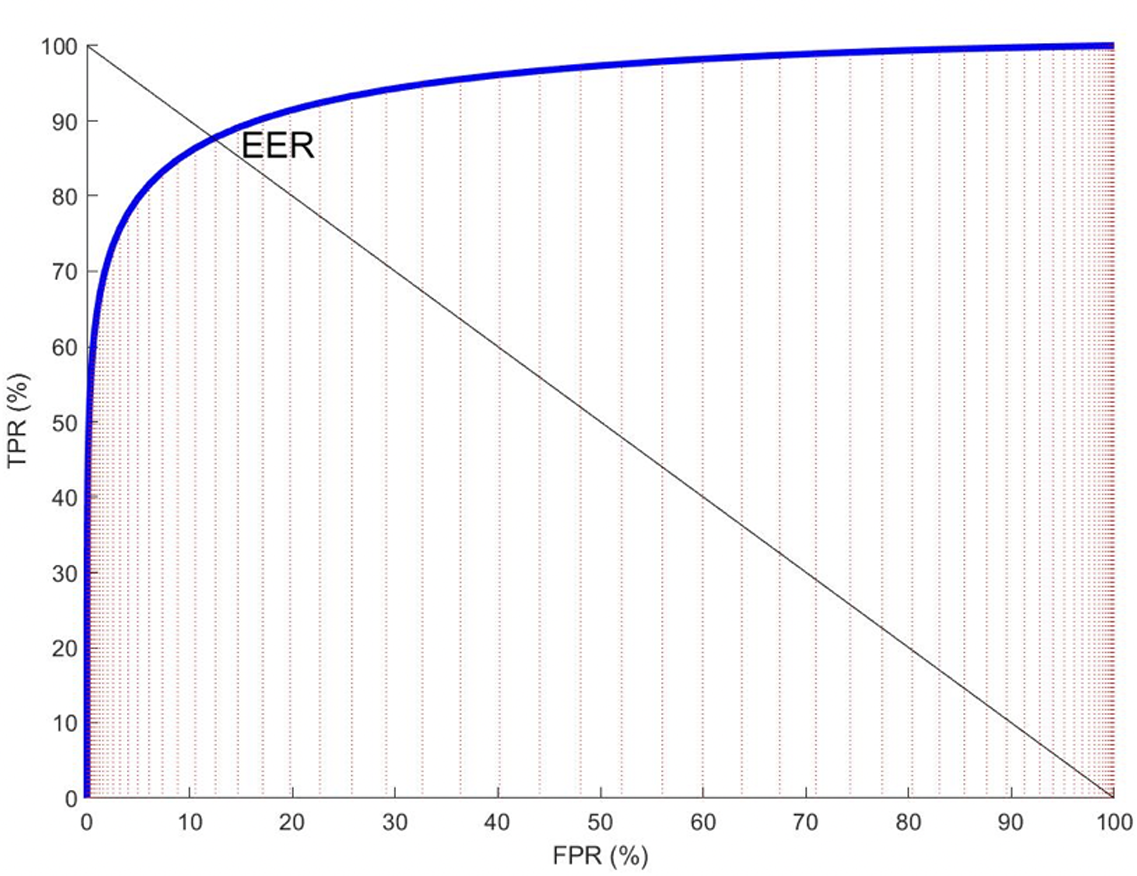
-
Area Under the ROC (AUC) The probability that a randomly chosen positive example is ranked higher than a randomly chosen negative example. (It means the perfect prediction if it equals to .)
- Scale-invariant Changing the range of the output will not change the AUC score.
- Threshold-invariant Given any threshold, the AUC score will not be changed.
Consider a set of binary samples indexed by for positive class, and for negative class. Let be a predictor and .
Consider also a Heaviside step function given by
Then AUC can be expressed by .
Unsupervised Learning
Clustering
Clustering is a problem of learning to assign labels to examples by leveraging an unlabeled dataset.
Dimensionality Reduction
Principal componentanalysis (PCA) is a technique that converts a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables, called principal components.
Density Estimation
Estimate the distribution based on some observed data.
-
Kernel Density Estimation (KDE)
where is a hyper-parameter called kernel size, which can be tuned using -fold cross-validation.
Autoencoder
An autoencoder is a type of artificial neural network used to learn efficient coding of unlabeled data.
Self-supervised Learning
Self-supervised learning (SSL) is a paradigm where a model learns from unlabeled data by automatically generating pseudo-labels from the data itself, without requiring human annotation.
K-means Clustering
Initialize centroids, assign each point to nearest centroid, update centroids by mean of assigned points, repeat until convergence.
In short, K-means will minimize the within-cluster variance, as follows:
where denotes is assigned to cluster .
Coordinate Descent
Assignment (Given to update )
Note that the assignment for each data can be solved independently, , pr
The solution can be obtained as follows
Refitting (Given to update )
Note that can be optimized independently, as follows
By setting the derivative as 0, ,
Since the objective function is non-convex, K-means may converge to a local minimum, and the final solution can be sensitive to the initial centroids. To mitigate this issue, it is common practice to run K-means multiple times with different random initializations and select the solution with the lowest within-cluster variance.
Performance Evaluation
Internal Evaluation Metrics (Silhouette Coefficient)
Define as the mean distance between a point and all other points in the same cluster. Define the smallest mean distance of a point to all points in any other cluster.
The silhouette coefficient for a single sample is formulated as follows:
close to indicates that the sample is well clustered.
External evaluation metrics (Rand Index)
| Symbol | Definition |
|---|---|
| same in , same in | |
| different in , different in | |
| same in , different in | |
| different in , same in |
For random clusterings, the expected value of the Rand Index is not zero. Let , and Adjusted Rand Index (ARI) is defined as follows:
Gaussian Mixture Models
where are the mixing coefficients, , , , and
Alternating Upadating Algorithm
The log-likelihood is given by
Derive the KKT conditions based on the Lagrangian function. Note that since the original objective is to maximize , this is equivalent to minimizing .
Let the derivate of with respect to be zero:
Let , then
Then let the derivate of with respect to be zero:
Last the derivate of with respect to is zero:
Algorithm
-
Initialize .
-
E-step Compute the responsibilities
-
M-step
First, compute the effective number of points assigned to component :
Then update the parameters:
-
Repeat steps 2 and 3 until convergence.
K-means vs. GMM
| Aspect | K-means | GMM |
|---|---|---|
| Cluster Shape | Spherical | Elliptical |
| Cluster Assignment (Step 1) | Assignment step: Assign each data point to the closest cluster (hard assignment). | E-step: Given the current model, compute the posterior probability over for each data point (soft assignment). |
| Model Updating (Step 2) | Refitting step: Move each cluster center to the center of gravity of the data assigned to it. | M-step: Given the posterior probability, update the model parameters by maximizing the expected log-likelihood. |
The Expectation-Maximization Algorithm
Jensen's Inequality
For a convex function , we have .
For a concave function , we have .
Proof (for convex function )
When , , , where . Then .
When , proof by induction applies. Assuming the inequality holds for variables, consider variables. The following relation holds Where . Then
Auxiliary Distribution of Latent Variables
Add a hidden variable to indicate which component generates , then the complete-data log-likelihood is given by
Let denote the observed data, denote the latent variables. The log-likelihood can be expressed as follows:
Let be an auxiliary distribution over the latent variables and they are independent, , with constraint . Then by using Jensen's inequality, we have
To extend the above equation to the whole dataset, we have
E Step
Given , the optimal is given by
The optimal is given by , the KL divergence is going to be zero.
M Step
Given , the optimal is given by
Substituting got in E step into the above equation,
EM Convergence
Application to GMM
E-step computes the posterior responsibility of each Gaussian for each data point, and M-step updates the parameters using weighted averages based on those responsibilities.
Set , then compute the expected log-likelihood as follows:
Given a data set with corresponding latent variables , the complete-data log-likelihood is
Next, maximize this expected log-likelihood with respect to to obtain closed-form updates for the M-step.
Principal Component Analysis
Given a dataset , PCA aims to find a projection matrix that maps the original data to a lower-dimensional space while maximizing the variance of the projected data.
Projection onto a Subspace
Let and -dimensional subspace is spanned by an orthonormal basis . The projection of a data point onto the subspace is given by
The vector is orthogonal to the subspace , , .
Principal Component Analysis Algorithm
Variance Maximization
Given a dataset , PCA aims to find a -dimensional subspace , such that the variance of the reconstructions is maximized, ,
Since , the above equation can be rewritten as follows
Note that the following derivations are equivalent by the Pythagorean theorem
Define the empirical covariance matrix as follows
Then the optimization problem can be rewritten as follows
By using the Lagrange multiplier to handle the constraint :
where .
Then the optimal can be obtained by setting the derivative of with respect to as zero:
Utilizing the SVD decomposition of
where are the eigenvalues of , and is the corresponding eigenvector.
Substituting the SVD decomposition of into the above equation:
where is the set of indices corresponding to the eigenvectors and with .
The Uncorrelatedness of Coveriance Matrix of Projected Data
Let , .
The covariance matrix of the projected data is given by
Let , then , and is the top-left block of . Then
Then the covariance matrix of the projected data can be rewritten as follows
where is a diagonal matrix. Therefore, the covariance matrix of the projected data is diagonal, which means that the projected data are uncorrelated, , for .